The horrors of the Episerver Link Validation Job
Preventing broken links is an important part of maintaining a website. Episerver’s Link Validating job tries to help us, but unfortunately, it has its shortcomings.
How it works
Episerver keeps track of all links and stores them a database table called tblContentSoftlink. This table has multiple uses.
It is used to provide warning messages if you try to delete content that is linked/referenced from other content. Like this:
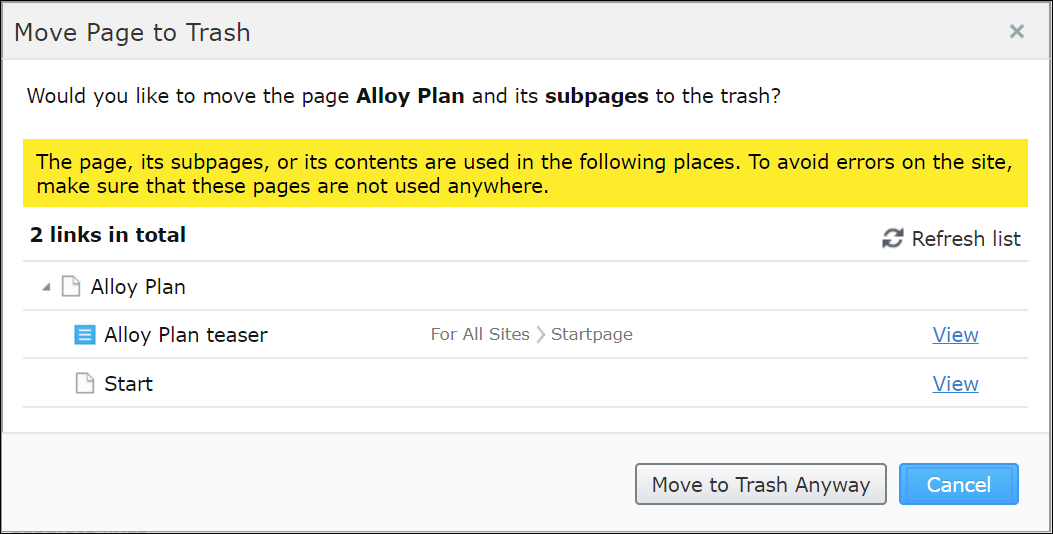
It is also used by the scheduled job EPiServer.LinkAnalyzer.LinkValidationJob to update the table tblContentSoftlink with information on what links are broken, and then the report Link Status in Report Center displays this information.
The scheduled job uses the stored procedure netSoftLinksGetUnchecked to get batches of 1000 rows/links from tblContentSoftlink that are either previously unchecked or last checked more than a configurable number of days ago. Every URL is filtered against the exclude pattern (we will come back to that) and then the link is checked. Internal links are checked using ContentLoader.Get() and external links are checked using System.Net.HttpWebRequest. The result is written back to the table tblContentSoftlink.
The problem
Over the past years, I have submitted approximately 10 bug reports regarding various problems with the Link Validation job. A recurring problem is that one single URL with an unexpected format causes the entire job to fail. When encountering a URL with an unexpected format, the job should mark the link as broken and continue with the next link. Instead, all sorts of exceptions show up in the logs, and the job terminates.
Last week Episerver finally released a fix to this bug that I have been trying to convince them to fix for the last five months. This fixed a problem when rechecking URLs from Report Center.
The solution
I mentioned the exclude pattern earlier, and in web.config you can configure how the validation job should behave.
<linkValidator
maximumRunTime="4:00:00"
recheckInterval="30.00:00:00"
internalLinkValidation="Api">
<excludePatterns>
<add regex=".*doc"/>
<add regex=".*pdf"/>
</excludePatterns>
</linkValidator>However, all different sorts of URLs have made the job fail. On a large site with 700.000 rows in the table tblContentSoftlink and more than 300 content editors, there always pops up one or more URLs that make the job crash. I would add a new exclude pattern, and then another URL would make the job crash again.
Instead of adding new exclude patterns every time the editors find a new way to be creative, I ended up using the exclude pattern like an «include pattern» instead.
Using a regular expression that does not match URLs that look valid as an exclude pattern, will in fact include only the URLs that looks valid.
<linkValidator
maximumRunTime="4:00:00"
recheckInterval="30.00:00:00"
internalLinkValidation="Api">
<excludePatterns>
<add regex="^(?!http(s)?:\/\/|~).*" />
</excludePatterns>
</linkValidator>The regular expression will match all links that do not start with any of the following:
- https://
- http://
- ~
To identify the URLs that get excluded from the job, use this SQL.
SELECT *
FROM tblContentSoftlink
WHERE
LinkURL NOT LIKE 'https://%' AND
LinkURL NOT LIKE 'http://%' AND
LinkURL NOT LIKE '~%'Then the job ran happily, and without exceptions, ever after.