Bulk deletion of Sanity documents using Sanity CLI, Notepad++ and regex
Using Sanity Studio, you can delete documents one by one. What if you want to delete hundreds of documents, or you have removed the schema definition so that your documents are no longer visible in Sanity Studio?
You can use the Vision plugin to query your data using GROQ, like shown in the screenshot below. But you can not use Vision to do mutations, i.e. updating the content.
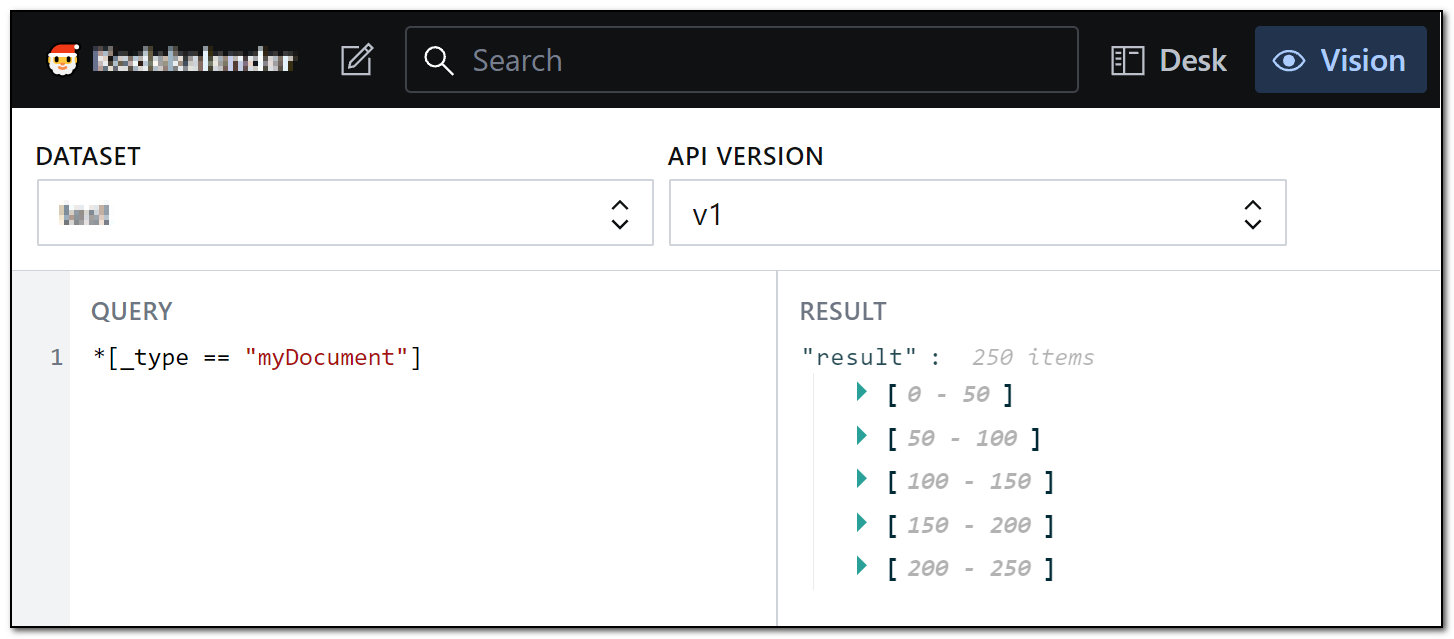
250 documents of type «myDocument» that I want to delete.
You can, of course, write code that does the mutations, or you can create a migration script and execute it from Sanity CLI. With some copy/paste and regex, you may use Sanity CLI alone, without needing to write any code.
Using Sanity CLI you can query your data like this, and get all documents of type myDocument.
sanity documents query "*[_type == 'myDocument']"A small change, because I only care about the _id property and I want to save the result to a file.
sanity documents query "*[_type == 'myDocument']{_id}" > mydocuments.txtI can then open the file in my favorite editor (Notepad++) and remove everything but the IDs, that I will be using with Sanity CLI.
Using the search mode for regular expressions, it's easy to remove everything but the ids.
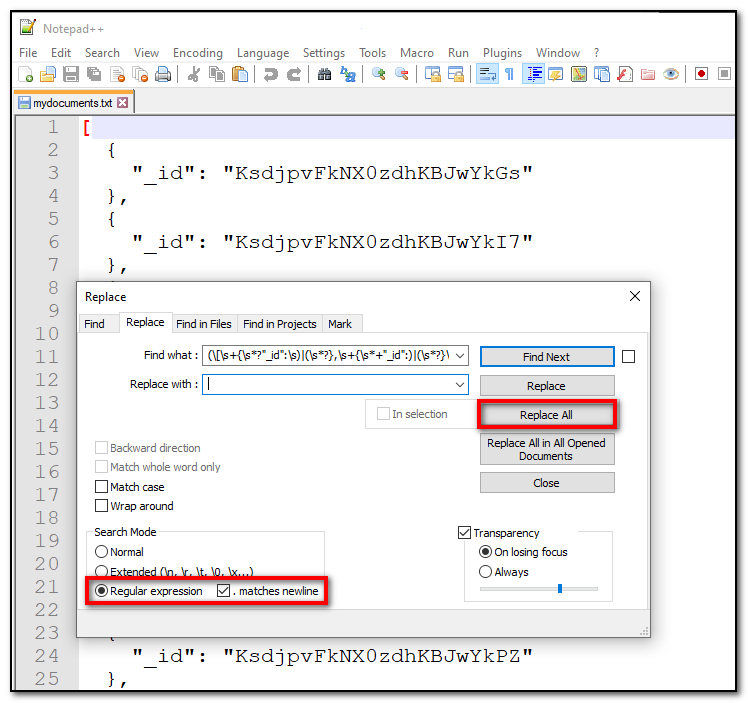
Search and replace all, in Notepad++.
The following regular expressions will do the trick.
(\[\s+{\s*?"_id":\s)|(\s*?},\s+{\s*+"_id":)|(\s*?}\s*?])The regular expression contains three parts that match the JSON structure before the first element, between the elements, and after the last element. I have checked the ". matches newline" checkbox in Notepad++, which allows for easier matching (and removal) of newlines.
A breakdown of the regular expression. The two last parts of the regular expression will also match the newline on the previous line. The first regular expression will match the space immediately before the id, the second will not match the space immediately before the id. The reason for this is that we need the space for separating the ids.
![Regular expressions: (\[\s+{\s*?"_id":\s)|(\s*?},\s+{\s*+"_id":)|(\s*?}\s*?])](/contentassets/7612684ddd15401d8c51ab4cbea27f51/regex.png)
What the three parts of the regular expression actually match.
After replacing all (with an empty string) I get a list of document ids.
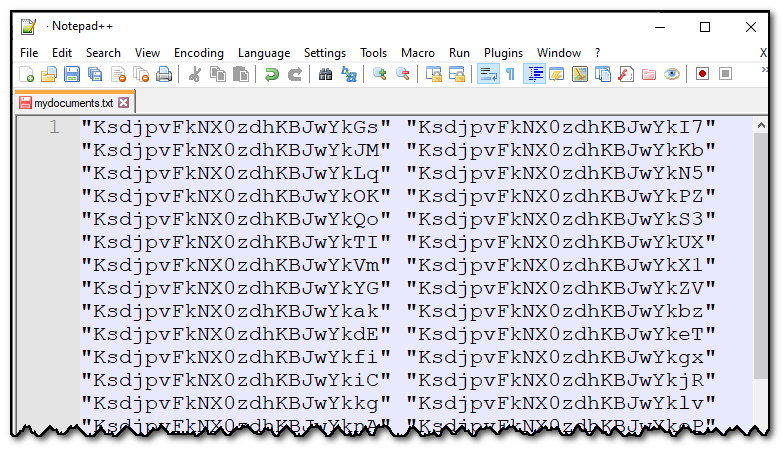
The list of documents ids, after regex replace.
This list of document ids, I can hand directly over to Sanity CLI. I enter the following command, then paste the list of document ids and press enter.
sanity documents delete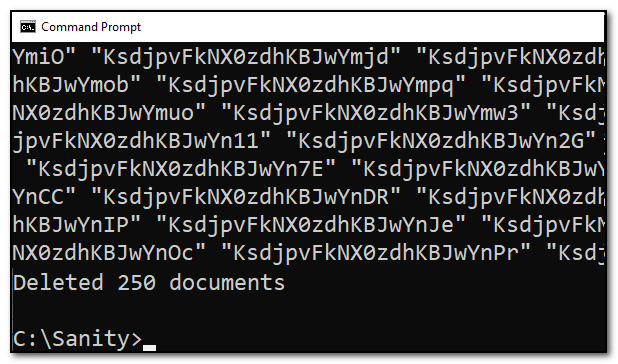
250 documents deleted at once.
That's it! All documents of the type myDocument have now been deleted.
Do you know an easier way?
Update: The above question were answered in the comments section, so I wrote another blogpost: Easier bulk deletion of Sanity documents, using Sanity CLI